Introduction
For machine learning models, Sensitivity parameter reflects on how sensitive the model is for classes under consideration. Sensitivity Analysis is generally performed before deployment of ML models in the real world application. The primary objective of the Sensitivity Analysis is to make ML model lean more towards certain class(es) than the other(s). Often the sensitivity analysis is also related to the study of the tolerance for misclassifying instances of certain class(es) against the other(s). For example, consider the machine learning model designed to detect faults in the industrial equipment. Generally, an operator want to always make sure that defects, if any, are detected almost always. In this case, an operator is OK (even though it is not ideal) if some non-defects are being recognized as defects. Because the cost of defects not being recognized as defects is very high as this may damage the equipment permanently. While there are also costs of classifying non-defects as defects, these costs are comparatively very less and can be filtered manually as false alarms. In general, ML algorithms should try to reduce the false alarms as well. In this blog, we will discuss how to perform sensitivity analysis on Qeexo AutoML platform.
Sensitivity Analysis
Qeexo AutoML performs the sensitivity analysis using Class Weights. For the classification problem having C, C >= 2, number of classes, class weights is a C-dimensional array of integers > 0. During the model training phase, Qeexo AutoML assigns the weight of 1 to each classes, i.e., the initial (or default) weight vector is C-dimensional array of 1’s which can be represented as  . This results in the initial sensitivity value of
. This results in the initial sensitivity value of  for each class represented as
for each class represented as  such that
such that
![\[ \sum _{i=1}^{C}s_i = 1\ \]](https://sensei.tdk.com/wp-content/ql-cache/quicklatex.com-d28b4371b3c248c6fae4c4b327d610d1_l3.png "Rendered by QuickLaTeX.com")
For example, for binary classification problem, i.e., 2-class classification problem, the default sensitivity array is  = 0.5, 0.5. If we start lowering one of the numbers, the model becomes more sensitive to that particular class. Lowering the sensitivity number of particular class is equivalent to increasing the weight of that class. All the model performance metrics such as Confusion matrix, Learning Curves, ROC curves, F-1 Score, and MCC are all computed with the default sensitivity value and class weights 1.
= 0.5, 0.5. If we start lowering one of the numbers, the model becomes more sensitive to that particular class. Lowering the sensitivity number of particular class is equivalent to increasing the weight of that class. All the model performance metrics such as Confusion matrix, Learning Curves, ROC curves, F-1 Score, and MCC are all computed with the default sensitivity value and class weights 1.
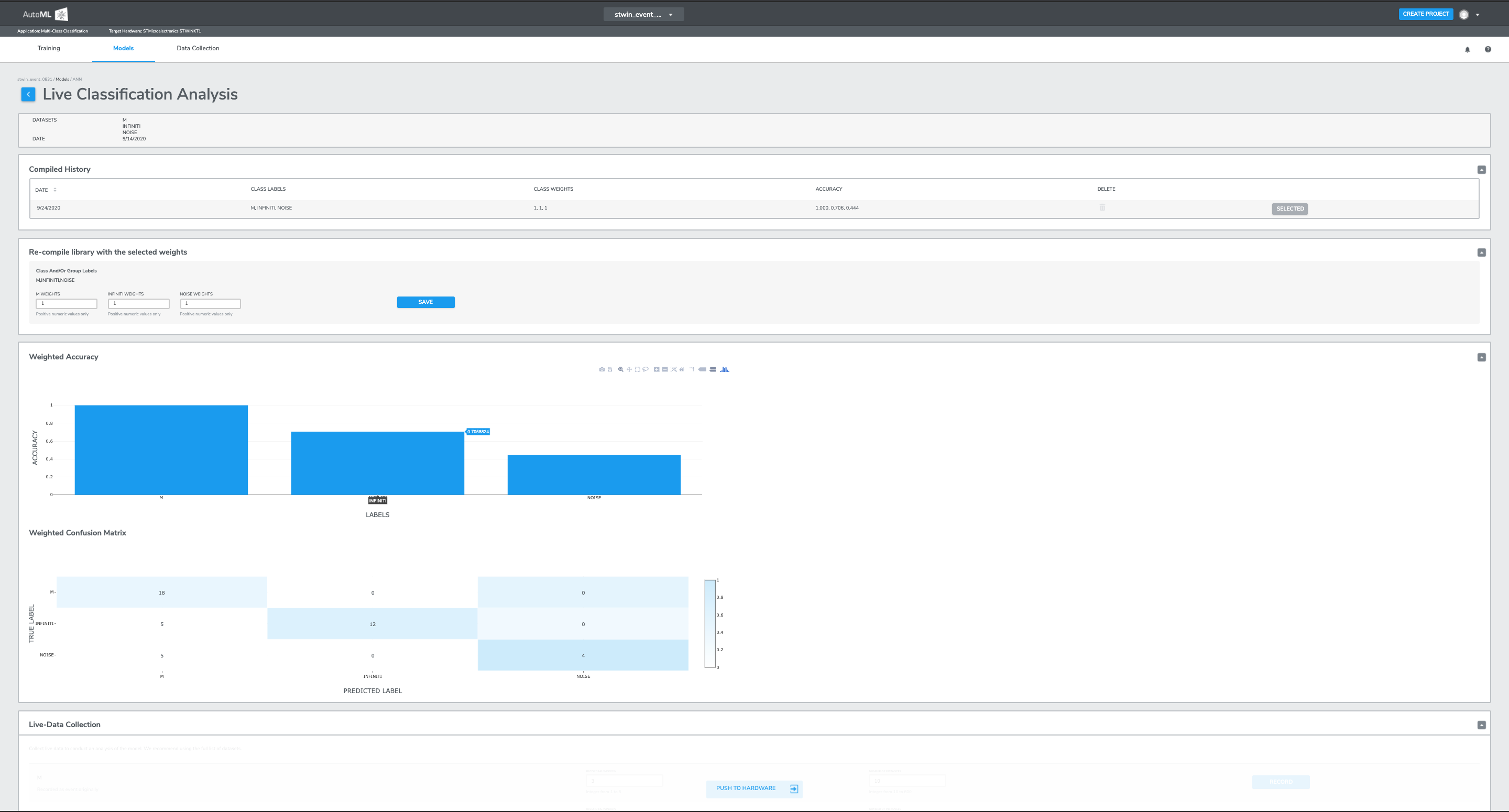
After training models on the Qeexo AutoML platform, you will be guided towards the Models page. Here you can see the details of each model and perform the live classification. You can go to the Live Classification Analysis to analyze the sensitivity of each class and update their influence on the model performance.

When you click into Live Classification Analysis icon, you can see the following page.

In the first tab, you can see the description of the model, such as the classes used in training and the date it has been created. The second section Compiled History will save the history of the weights you have tried; when you click this for the very first time, it will show the default weights of 1 for each class. It also allows you to select and delete any of the weights combination in your history. The selected weights will be updated on your device once you click Selected on this page and push the library to the device with the button in the Live-data Collection tab or on the Model page.
The bigger the weight is, the more sensitive the model is to that class. In other words, the model is more likely to output class with the higher weight. Even though you can assign a weight to each class, only the relative differences between the class weights matter. That is, for three-class classification, weights {1,1,1} will have the same effect as {3, 3, 3} because this simply means each class has equal weights.
In the third tab, you can try different combinations of weights and see the simulation of their effects on model performance. The model performance is shown through two metrics. One is the bar chart showing the the accuracy of each class with the chosen weight combination. The second one is through the confusion matrix. The y-axis of this table is True Label, the x-axis is Predicted Label. The values on diagonal from top left to bottom right of this table is where predicted label matches true label. The perfect performance shown by confusion matrix should have zeros everywhere except the diagonal cells.
The last part of this page offers a chance to collect some new testing data and evaluate the model with the selected weights on the testing data.
Some Examples
Let us first take a look at a binary classifier example. For binary classifier, the default classification rule is the following:
![\[ y= \begin{dcases} class_1, & \text{if} P(class_1) > 0.5\\ class_0, & \text{otherwise} \end{dcases} \]](https://sensei.tdk.com/wp-content/ql-cache/quicklatex.com-0b8d18a1a4d61bdd55a59ef21931d91a_l3.png "Rendered by QuickLaTeX.com")
However, in reality, in order to make the classifier more sensitive towards class-0 using this model, we want to make the following classification rule:
![\[ y= \begin{dcases} class_1, & \text{if} P(class_1) > 0.75\\ class_0, & \text{otherwise} \end{dcases} \]](https://sensei.tdk.com/wp-content/ql-cache/quicklatex.com-8ced2c8d2e82652aecf0b75f33ff8cdc_l3.png "Rendered by QuickLaTeX.com")
The new classification rule is stricter for class-1 and relaxed for class-0. This may be the better model compared to the default model because we may want to detect class-1 only if probability assignment of class-1 is highly confident, e.g.  , otherwise we want to classify the incoming signal (or pattern) into class-0. With this classification rule, the model remains the same but becomes more sensitive to one class over the other(s). In order to achieve this classification rule, the weights are computed as given below:
, otherwise we want to classify the incoming signal (or pattern) into class-0. With this classification rule, the model remains the same but becomes more sensitive to one class over the other(s). In order to achieve this classification rule, the weights are computed as given below:

For example, the models assigned the probabilities to each class as {0.4, 0.6}. With new weights, the weighted probabilities are:
![\begin{align*} weighted\_probability= [2, 0.67] * [0.4, 0.6] = [0.80, 0.40] \end{align*}](https://sensei.tdk.com/wp-content/ql-cache/quicklatex.com-0f264a42eb0b43bf2595f1a179458f10_l3.png "Rendered by QuickLaTeX.com")
Now we need to compare weighted_probability with the default thresholds {0.5,0.5}, that results in the classification decision class-0. With the concept of weights for classes, we have achieved the effect as if the sensitivities are {0.25, 0.75} for each class. Please note, without weights, this signal would have classified to class-1. However, with relaxed sensitivity value for class-0 and stricter sensitivity value for class-1, we get the classification outcome as class-0. Note that the sum of probabilities doesn’t equal to 1. We can also normalize the probabilities and get the same prediction.
![\begin{align*} normalized\_weighted\_probability= [0.80/(0.8 + 0.40), 0.40/(0.80 + 0.40)] = [0.666, 0.333] \end{align*}](https://sensei.tdk.com/wp-content/ql-cache/quicklatex.com-1775fe4398225f68aa334dec12cea7e3_l3.png "Rendered by QuickLaTeX.com")
This weighted probability compute generalize very well with multi-class classification with each class having its own threshold.
Conclusion
For real-world applications, finding the right weights for each class is a matter of trial-and-error or some predefined human knowledge. Qeexo AutoML offers very efficient method to test with different class weights, quickly check the classification performance, and then push the newly determined class weights in order to perform the live testing.