Deep learning (DL) has gradually become one of the most popular areas in artificial intelligence after the 1990s. Deep learning is a branch of machine learning and uses neural layers to build models. It combines low-level features and gradually forms abstract representation features to model the input data. Deep learning builds neural networks that simulates the human brain for analysis and learning. It mimics the mechanism of the human brain to interpret data, such as images, sounds, texts, and sensor readings.
According to the Universal Approximation Theorem [1], if a feedforward neural network has a linear output layer and at least one hidden layer with finite number of neurons and sigmoid activation function, it can approximate any continuous functions on a compact subset of ℝn with a sufficiently small error e > 0. This theorem is considered to be the theoretical basis of neural networks in deep learning.
The training process in deep learning is not particularly different from ordinary machine learning models. In deep learning, the objective is to find the weights of neurons or parameters of convolution filters in each layer, and this is done through predefined loss function, using gradient descent to continuously reduce the predefined loss, and strive to achieve the convergence. Backpropagation algorithm is the most common method for training neural networks. The algorithm will first calculate (and cache) the outputs of each layer according to the forward propagation, and then calculate the partial derivative of the loss function by applying chain rule with respect to each parameter in the way of traversing the graph backwards.
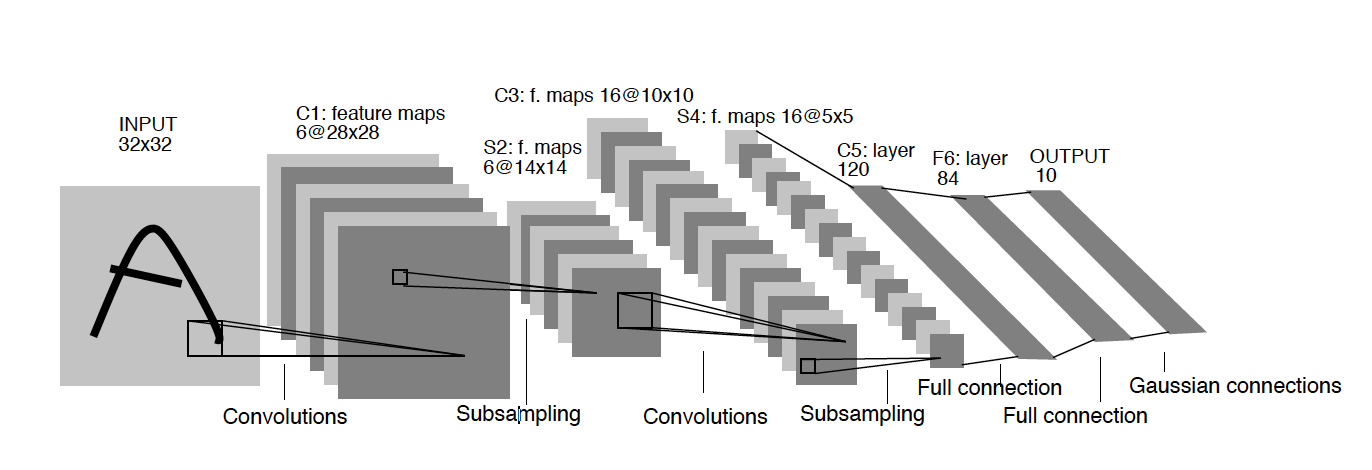
Deep neural networks, such as several common convolutional neural network models shown in the figure 1 [2], often have many parameters. Their parameters can often be in several thousands to millions depending on the application and size of the datasets presented for the learning. In the field of machine learning, the collection and labeling of training data is often a complicated and cumbersome process, which requires huge human and other resources. Thanks to Qeexo AutoML, the collection and labeling of the datasets is all integrated in the platform.

Tuning of deep learning model parameters is another challenge. For example, selecting the depth of the neural network, size of the convolution filters for each layer, what pooling to use, number of neurons in each layer, the learning rate, the optimization function, the batch size, number of training epochs, etc., often requires machine learning engineers to debug based on their knowledge and experience. This tuning process can be frustrating and time consuming. Deep learning is often very sensitive to model parameters, and the selection of model parameters will also affect the accuracy, size, and latency of the resulting model.
According to different learning tasks, commonly used models in deep learning include feedforward neural networks, convolutional neural networks, and recurrent neural networks. Qeexo AutoML platform for sensor data makes use of all these deep learning architectures for machine learning on micro-controllers. Due to memory, computation, and power consumption limitations on micro-controllers, Qeexo performs very sophisticated optimizations and model compressions on these architectures. Qeexo AutoML deep learning architectures does not require runtime interpreters when deployed on the microcontrollers. Libraries with no runtime make these models better suited for microcontrollers, they are light weight and has low latency.
Qeexo AutoML performs hyper-parameter tuning for deep learning models, saving time and effort of users dealing with this cumbersome process. Users also have a choice of configuring these model parameters themselves and if these parameters tend to generate models which are bigger than available memory size on the embedded devices, it performs automatic model reduction to make sure it fits on the device without sacrificing the model performance significantly.
Qeexo is one of the world’s first companies to run Deep Learning-based models from mobile phones. These models are light weight with latencies as low as 10 mSec. on mobile phone’s application processors. Qeexo’s AI engines are running on more than 300 Million mobile devices and growing rapidly. Today, Qeexo AutoML builds and deploys deep learning models on embedded targets using various sensor signals. Qeexo uses its proprietary model conversion technique to build light weight deep learning models on embedded microcontrollers. Additionally, Qeexo AutoML supports quantization-aware training of deep learning models. This type of training is aware of the fact that models are going to be quantized post-training and strives to retain the performance of the model despite quantization. Quantization can further reduce the model size while striving to maintain accuracy. This approach makes it possible to build bigger models when required to achieve high accuracy for certain applications.
References:
- Cybenko, G., “Approximations by superpositions of sigmoidal functions”, Mathematics of Control, Signals, and Systems, 1989, 2(4), 303–314.
- LeCun, Yann, et. al. “Object recognition with gradient-based learning.” Shape, contour and grouping in computer vision. Springer, Berlin, Heidelberg, 1999. 319-345.