In machine learning, the quality of feature selection strongly affects the quality of the trained model. Feature selections approaches differ depending on the type of machine learning problem, e.g., supervised learning or unsupervised learning. For supervised learning algorithms two most popular feature selection techniques are Wrapper-based and Model meta-transformer approach. For unsupervised learning algorithms, filter-based approaches are widely used.
In the part-I of this article, we will look into the wrapper-based feature selection approaches used for supervised learning problems.
Wrapper methods:
This approach keeps underlying ML algorithm in the loop with different subsets of features and sets the objective function quantifying the performance of the model, e.g., cross-validation score. Based on the strategy it adopts to iterate over different subsets of features, wrapper methods can further be categorized into exhaustive search, forward selection, backward selection, and k-best.
- Exhaustive search as its name suggests creates all the possible subsets of the actual feature sets and recommends the best subset according to the criterion. This approach is very time consuming as for p number of features it needs to evaluate 2p-1 combinations. For large p, this approach is almost impractical.
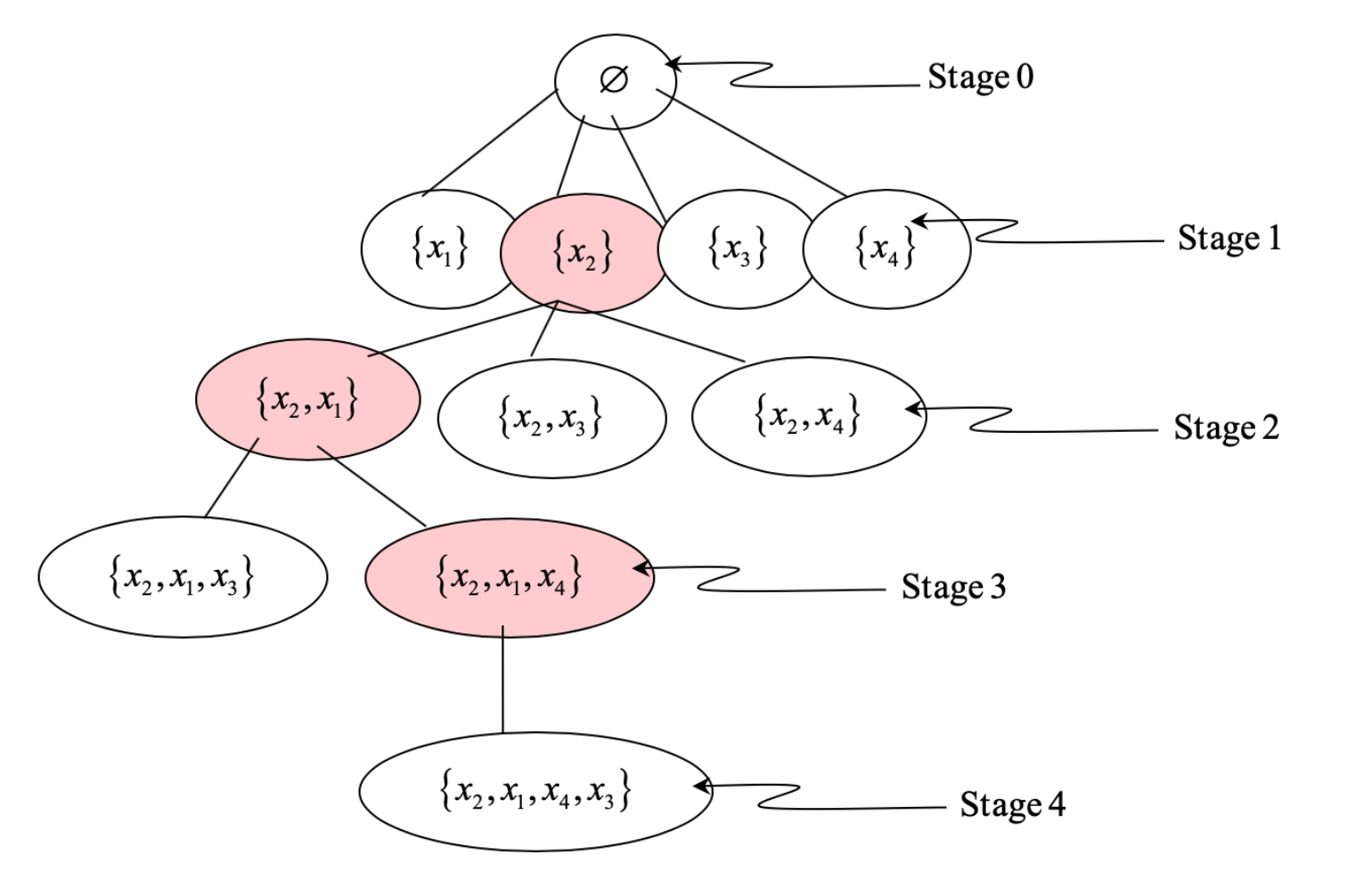
- Forward selection starts with zero features, evaluates each 1-feature model according to the defined criterion, and keeps the best performing feature at the root. Then makes 2-feature combination with the selected best and repeats the procedure until any further gain in the performance criterion cannot be achieved or all the features are exhausted. Fig. 1 explains the example run of forward selection algorithm with four features in the original set, X = {x1, x2, x3, x4}. Note the highlighted feature groups at each stage of the algorithm and algorithm termination with selected features {x2, x1, x4} because either the performance of {x2, x1, x4} is greater than or equal to {x2, x1, x4, x3}. For p number of features, this approach in the worst case evaluates p*(p+1)/2 combination of features instead of 2p-1 exhaustive combinations.
- Backward elimination first builds model with all the available features and recursively removes the least significant feature. The least significant feature can be identified by building models with all but one feature at a time and finding the drop in the performance. A feature which results in the performance drop of more than the threshold should be removed from the pool. The process continues until all the features with least significance are removed.

4. k-best approach is basically equivalent to running only the first stage of forward selection approach. It ranks each feature according to its performance on the defined criterion and can be cross-validation performance. Then it chooses the top k features, where k can be specified according the requirements on the memory, compute power, and latency.
Qeexo AutoML Feature Selection:
AutoML runs grouping-based forward selection wrappers method for feature selection to achieve the best model performance and smaller memory footprint libraries with low latency. To deal with continuously streaming data from multiple sensors at many different sampling rates, AutoML extracts hundreds of features from these streams. Some of these sensors are even multi-channel sensors, e.g., accelerometer, gyroscope, and magnetometer have three dimensional streams, colorimeter has four dimensional streams, etc. Multiple dimensions add to the complexity of feature space. To deal with such a large and complex feature space, AutoML categorizes feature space into several groups, for example, statistical-based, frequency-based, filter bank-based, etc. AutoML then runs forward feature selection algorithm on groups and recommends best feature groups.
AutoML expert mode also expose feature groups for each sensor to the user and then users can manually choose the feature groups. This approach allows users to rapidly iterate and trade off among various criteria library size, performance, and latency. In built visualizer projects the feature groups to 2-dimensional embedding space to visualize the classification properties of the selected group of features to guide the user selection.
For one-class problems, e.g., anomaly detection, Qeexo’s AutoML platform uses different methods to perform feature selection. These methods will be covered in Part-II.