Introduction
Sound Recognition is a technology based on traditional pattern recognition theories and signal analysis methods which is widely used in speech recognition, music recognition and many other research areas such as acoustical oceanography [1]. Generally, microphones are regarded as sufficient sensing modalities as input to machine learning methods within these fields. Microphones are capable of capturing information necessary for the variety of classification tasks that can be performed on lightweight devices. With this type of sensor, Qeexo AutoML provides a diverse feature stack, taking advantage of the physical properties of microphone data to extract information relevant to such classification tasks. This blog will show you how to perform sound recognition with Qeexo AutoML and explain some of the basics concepts of our feature stack.
AutoML Tutorial
Qeexo AutoML offers a general use user-friendly interface for engineers who wants to perform sound recognition, or any other classification task on embedded devices. The processes discussed in this blog are not specific to sound recognition, but are specifically applicable to it. To get started, navigate to the training page and select (or upload) the labeled training data that you want to use to build models for your embedded device. In the Sensor Selection page, you can select the desired sensor types, (in our sound recognition example we utilize the microphone sensor), to choose the collected data, as shown in Figure 1.

You are also provided with the option of automatic sensor and feature group selection, if you want to use additional sensor modalities or experiment with feature subgroups. If this is selected, Qeexo AutoML will automatically choose the sensor and feature groups that make the classes most distinct. In the Inference Settings page, you can manually set up the instance length and the classification interval, or let Qeexo AutoML determines them by selecting Determine Automatically, as shown in Figure 2.

In the Model Settings page, you can pick the algorithm(s), choose whether to generate learning curve and/or perform hyperparameter tuning and click Start Training button to start. After the training is finished, a binary file will be generated and can be flashed to the device by clicking the Push to Hardware button. Once the process is finished, you can perform live tests on the model that was built, as shown in Figure 3.

While the process is by design very straightforward, the details of some of the choices may appear ambiguous.
Other blog posts go into some detail on different aspects of the pipeline, but we will focus on some of the feature
choices applicable to sound recognition.
Sound Recognition Highlighted Features
Fast Fourier Transform (FFT)
Signals in the time domain are difficult for humans and computers alike to distinguish among similar sound sources. One of the most popular ways to transform raw sound data is the Fast Fourier Transform (FFT). Due to the constraints of embedded devices, the FFT is an efficient frequency decomposition technique. The process is described in Figure 4.

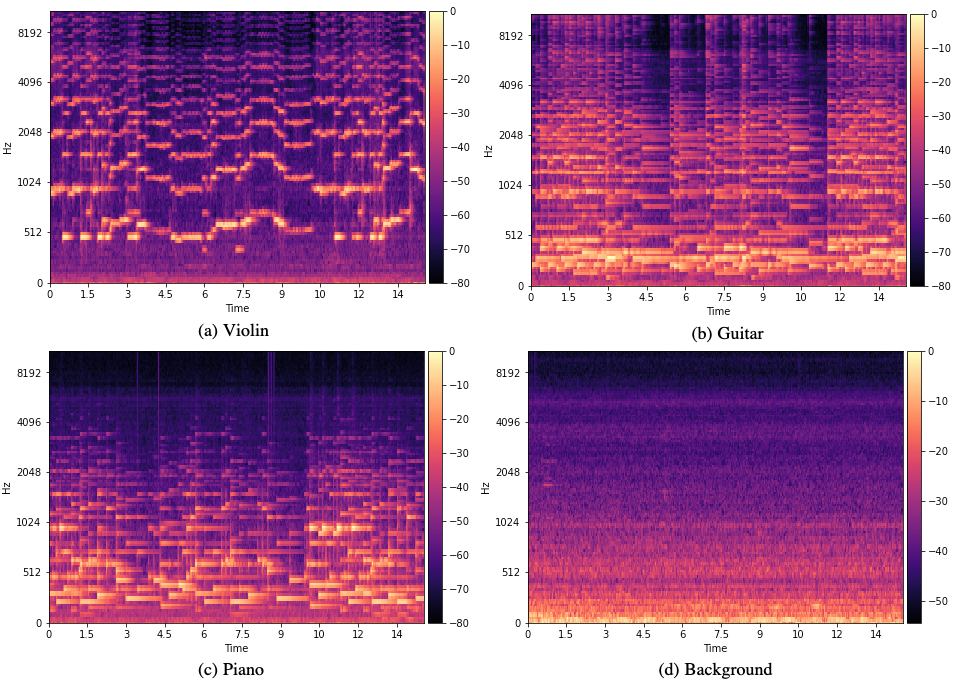
For different classes, the signals differ in their magnitudes for a given frequency bin. E.g., in Figure 5, sounds generated with different instruments have different distributions of the magnitudes among the frequencies 0-800 Hz; even with differences present up to 2000 Hz.

The Qeexo AutoML training methods will take advantage of the increased class separability in this range to train the model through model training. Qeexo AutoML doesn’t just use all of the FFT coefficients as input in training the model, but actually aggregate the coefficients to create sophisticated features. The specific groupings can be hand-picked during the model selection process to accommodate implementation constraints. To select the features groups, simply check the box(es) in the manual feature selection page as shown in Figure 6.

Mel Frequency Cepstral Coefficients (MFCC)
Mel Frequency Cepstral Coefficients (MFCC) is also an important technique for sound recognition. Humans react differently to distinct ranges of frequencies. As a species, we are more capable of telling the difference in frequencies between a 50Hz and a 100 Hz signal, than that between 10050Hz and 10100 Hz. In other words, we are really bad at distinguishing high pitched sounds. Therefore, in situations where you want to replicate a task performed by humans, such as voice separation, the difference when the frequency is low is the most important. The value of the signal properties decreases with increasing frequency. Mel scale comes into place here, by assigning more importance to the low frequency content and less to the high frequency content. The formula for converting from frequency to Mel score is:

We build a filter bank containing many triangular filters and apply them to our FFT features to rescale the signals again and convert them to the corresponding Mel scales. In the Mel spectrograms shown in Figure 7, we can see that different classes’ Mel spectrograms appear to have many differences, making them ideal inputs for training a classifier.

Qeexo AutoML also provides features generated from the coefficients of MFCC. The feature groups can also be selected in the manual selection page shown in Figure 3. If desired, you can visualize the selected features through a UMAP plot by clicking the Visualize button shown in the Sensor Selection page and Feature Group Selection page.
Based on this discussion, it should be apparent that MFCC features will work well for tasks involving human speech. Depending on the task, it may be disadvantageous to include these MFCC features if it does not share similarities with human hearing. Qeexo AutoML performs automatic feature reduction, however, when automatic selection is enabled, so this does not need to be an active concern when training models. If the MFCC features are not highly separable for the task, assuming sufficient data is provided, they will be dropped from the final model during this process.
Conclusion
Qeexo AutoML not only provides model building functionality, but also present the details of the trained models. We provide evaluation metrics like confusion matrix, by-fold cross validation, ROC curve, and even support downloading the trained model to test it elsewhere. As mentioned earlier, we provide support for, but do not limit to microphone sensor usage for sound recognition. You are free to select any other provided sensors such as accelerometer and gyroscope. If these additional sensors don’t improve model performance, they won’t be included in the final device library, through the automated sensor selection process.
Bibliography
[1] Wikipedia: Sound Recognition,
https://en.wikipedia.org/wiki/Sound_recognition