
Qeexo AutoML supports three one-class classification algorithms widely used for anomaly/outlier detection; Isolation Forest, Local Outlier Factor, and One-class Support Vector Machine. These algorithms build models by learning from only one class of data. After learning, anomaly detection algorithms determine whether a test instance belongs to the normal class or if it is an anomaly. Qeexo has taken one-class approach for anomaly detection because it is easy to collect the data from normal class (e.g., normal operation of a machine) compared to doing multi-class data collection where each type of anomaly represents one class.
Isolation Forest (IF) [1]
Isolation Forest is an efficient algorithm for outlier detection, also very effective in high-dimensional datasets. It builds an ensemble of decision trees in which each tree is trained randomly; at each node in the trees, it picks a feature randomly, then it picks a random threshold value (between minimum to maximum value of the feature) for splitting the dataset. The trees are grown until all the instances are isolated from other instances. The anomalies generally tend to be far away from normal instances. The number of divisions required to isolate a sample from other instances is equivalent to the path length from the root node to the terminating node in the tree. The path length, averaged over all the trees, produces noticeable shorter paths for anomalies, and comparatively longer paths for normal data.
The average path length over the collection of isolation trees, referred as E(h(x)) in [1], is used to compute the anomaly score as:
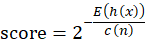
Where ![]() is the total number of instances in training data and
is the total number of instances in training data and ![]() . The
. The ![]() is the harmonic number.
is the harmonic number.
Local Outlier Factor (LOF) [2]
LOF algorithm compares the density of instances around a given instance with the density around its neighboring instances. The distances of the given instance with respect to its k-nearest neighbors are used to estimate its local density. The LOF compares the local density of the given instance to the local densities of its neighbors. Instances that have substantially lower density than their neighboring instances are considered as outliers.
If we consider some data points in a space, the reachability distance of a data point p with respect to data point o is defined as:
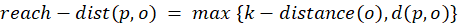
where k is the number of neighbors considered in this calculation. The k-distance(o) is the distance of the data point o to its kth farthest data point from the dataset. The d(p, o) is the distance between data points p and o.
The reachability distance is used to calculate local reachability density (LRD). The (LRD) is inverse of the average reachability distance based on the k-neighbors of data point p. It can be written as:
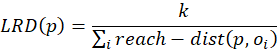
Finally, the LOF of a data point p is average of the ratio of LRD of the p and those of its k-neighbors.
One-class SVM (OCSVM) [3]
OCSVM tries to separate instances in high-dimensional space from the origin. In original space, this corresponds to finding a small region which encompasses all the instances. If a given instance doesn’t lie in this small region, then it is considered an anomaly. The OCSVM makes use of quadratic programming to solve the optimizing problem for finding the coefficients corresponding to the support vectors.
The objective function of the model for separating the data from the origin is written as:
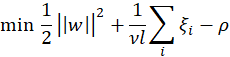
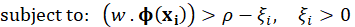
The ![]() variables are non-zero and are penalized in the objective function. Thus, the decision function for an instance becomes
variables are non-zero and are penalized in the objective function. Thus, the decision function for an instance becomes ![]() which will be positive for most of the training data points while having the regularization term
which will be positive for most of the training data points while having the regularization term ![]() to be small. The variable
to be small. The variable ![]() controls the trade-offs between these two goals.
controls the trade-offs between these two goals.
Mapping Anomaly Scores to Range of 0 to 1
Qeexo AutoML internally squashes anomaly scores from different models in the range (0,1]. This is done to have consistent view of anomalies across all the algorithms which in turn assists in better calibration of the anomaly threshold. An instance is called an anomaly if the output of the squashing function is larger than a threshold value. The default value of the threshold in AutoML is 0.5. The user has the option to calibrate the threshold to make the predictions biased towards inliers or outliers.
Advantages of Qeexo AutoML Anomaly detection:
- Only Normal class data is required. It is extremely difficult and sometimes even impossible to collect data for different kinds of anomalies. Qeexo AutoML need data only from one class.
- Easy calibration of anomaly detection threshold with live streaming of scores and live classification
- Support of multiple algorithms described in this blog with Quantization support for Isolation Forest
- Can also be utilized for other one-class applications such as detecting unique air gesture using magic wand against all other gestures
- Support for Automatic and Manual selection of features
Example Case
An application of anomaly detection for machine monitoring can be found here: https://qeexotdkcom.wpengine.com/detecting-anomalies-in-machine-data-with-qeexo-automl-2/
References:
[1] Liu, F. T., Ting, K. M., & Zhou, Z. H. (2008, December). Isolation forest. In 2008 Eighth IEEE International Conference on Data Mining (pp. 413-422). IEEE.
[2] Breunig, M. M., Kriegel, H. P., Ng, R. T., & Sander, J. (2000, May). LOF: identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD international conference on Management of data (pp. 93-104).
[3] Schölkopf, B., Williamson, R. C., Smola, A. J., Shawe-Taylor, J., & Platt, J. C. (2000). Support vector method for novelty detection. In Advances in neural information processing systems (pp. 582-588).